Стан системи та потенційні проблеми
Інструменти стану системи допомагають помітити операційні проблеми до того, як вони призведуть до втрати трафіку, зламаного трекінгу або недоступних сторінок кампаній.
Використовуйте цю статтю, коли дзвіночок сповіщень показує попередження, routing кампанії виглядає незвично або потрібно перевірити, чи сервер трекера працює стабільно.
Як інструменти перевірки працюють разом
У Bangi є три основні місця для перевірки проблем:
| Інструмент | Що показує | Коли використовувати |
|---|---|---|
| Сповіщення | Короткий список активних проблем, які потребують уваги | Починайте звідси, коли іконка дзвіночка підсвічена |
Health |
Діагностику сервера, сертифікатів і Nginx | Використовуйте для інфраструктурних і доменних проблем |
Discards |
Трафік, який дійшов до кампанії, але не потрапив у жоден flow | Використовуйте для проблем із routing кампанії та правилами flow |
Сповіщення працюють як сигнал тривоги: вони показують, що щось потребує уваги. Health і Discards допомагають зрозуміти, де саме виникла проблема.
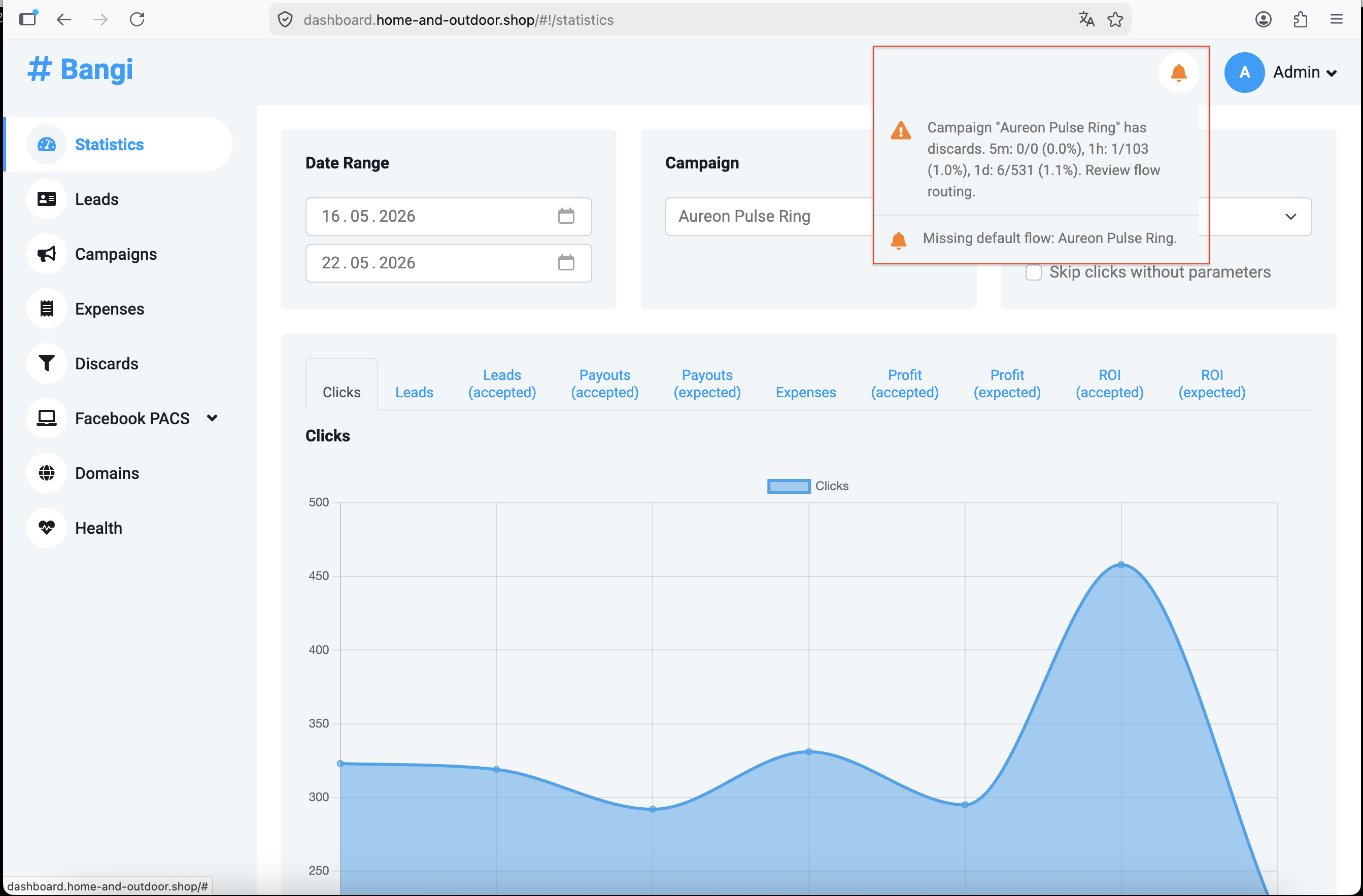
Перевірте сповіщення
Іконка сповіщень розташована в "шапці" панелі керування. Коли є активні сповіщення, дзвіночок змінює колір залежно від найсерйознішої проблеми:
| Severity | Значення | Рекомендована дія |
|---|---|---|
Info |
Щось виглядає незвично, але не обов'язково терміново | Перегляньте, коли буде зручно |
Warning |
Проблема може скоро вплинути на трафік, трекінг або роботу системи | Перевірте найближчим часом |
Error |
Проблема вже серйозна або може зламати важливу поведінку | Перевірте негайно |
Розгорніть список сповіщень, щоб прочитати кожне повідомлення. Зазвичай повідомлення підказує, яка частина системи зачеплена і що потрібно перевірити далі.
Панель керування автоматично перевіряє сповіщення приблизно раз на 10 хвилин. Після виправлення проблеми сповіщення може залишатися видимим до наступного оновлення. Якщо потрібно перевірити одразу, оновіть сторінку dashboard вручну.
Типові групи сповіщень:
| Група сповіщень | Що зазвичай означає | Де перевіряти |
|---|---|---|
| Диск або stale telemetry | Місце на сервері закінчується, стан критичний або давно не було disk report | Health |
| Certificate | Сертифікат домену expired, скоро expired або не може бути виданий чи оновлений | Health і Domains |
| Nginx validation | Остання перевірка конфігурації Nginx завершилася помилкою | Health |
| Campaign discards | Кампанія отримала трафік, який не підійшов під жоден flow | Discards і налаштування flows кампанії |
Перевірте стан системи в Health
Перейдіть у Health через sidebar панелі керування.
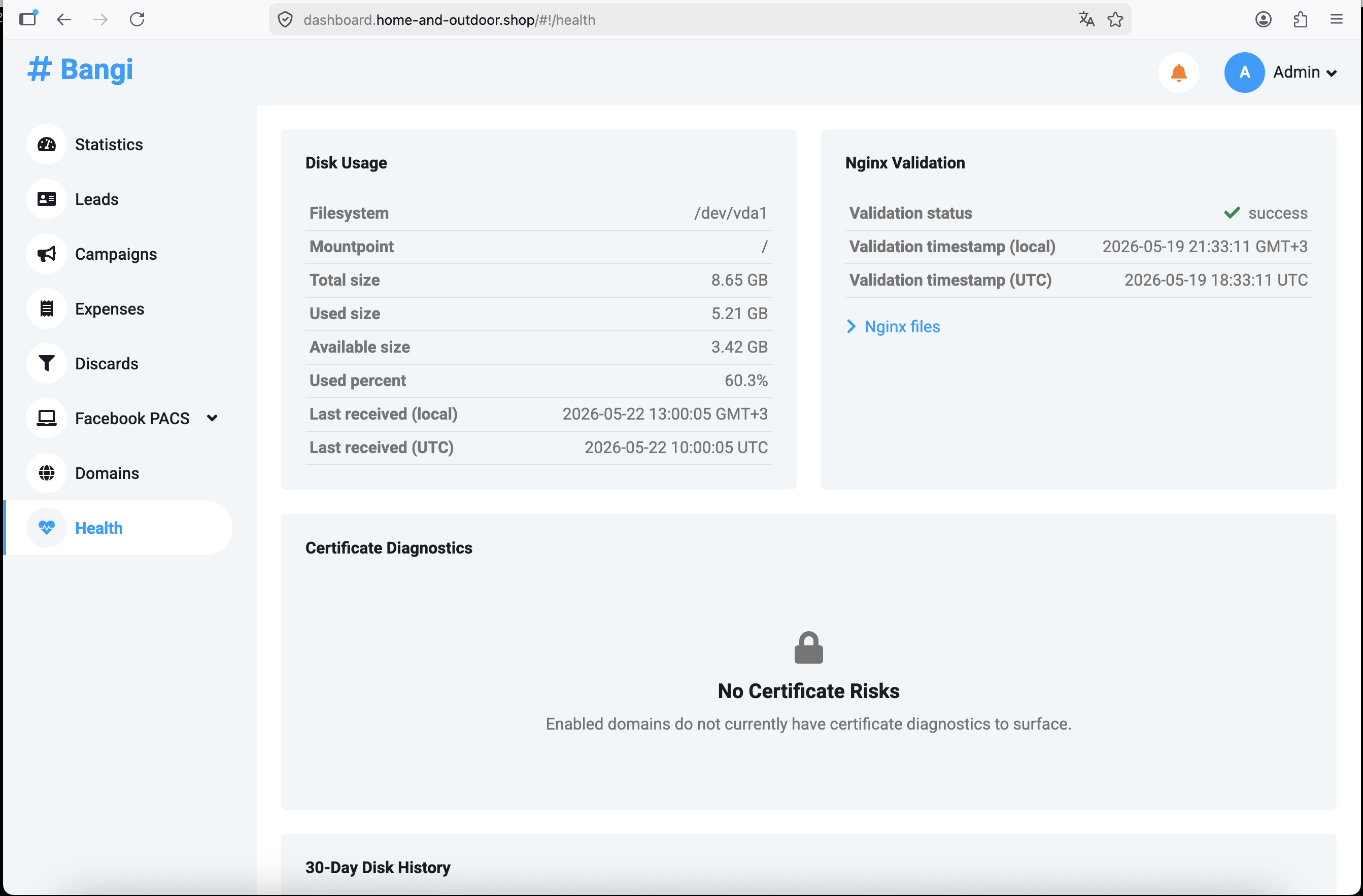
Сторінка Health має чотири основні області:
| Область | Призначення |
|---|---|
Disk Usage |
Показує останній стан використання диска на сервері трекера |
Nginx Validation |
Показує, чи пройшла перевірку остання опублікована конфігурація Nginx |
Certificate Diagnostics |
Показує ризики сертифікатів доменів і готовність DNS |
30-Day Disk History |
Показує тренд використання диска за останні 30 днів |
Використовуйте цю сторінку, коли сповіщення згадують disk usage, telemetry, certificates або Nginx.
Disk Usage
Панель Disk Usage показує filesystem сервера, mountpoint, загальний розмір, використаний обсяг, доступний обсяг, used percent і час отримання останньої telemetry.
| Сигнал | Значення | Що робити |
|---|---|---|
| Used percent у нормі | На диску достатньо вільного місця | Дія не потрібна |
| Used percent високий | Сервер наближається до warning threshold | Заплануйте cleanup або збільшення диска |
| Used percent критичний | На сервері скоро може закінчитися місце | Негайно звільніть місце або збільшіть диск |
| Telemetry is stale | Трекер давно не отримував disk usage report | Перевірте, чи працює telemetry job на сервері |
| Never Reported | Disk telemetry ще жодного разу не надходила | Дочекайтеся першого report або перевірте налаштування telemetry |
Високе використання диска може вплинути на записи в базу даних, logs, оновлення сертифікатів та інші background jobs. Критичні сповіщення про диск варто обробляти як термінові.
30-Day Disk History
Використовуйте 30-Day Disk History, щоб зрозуміти, чи використання диска стабільне, чи поступово зростає.
Практичні приклади:
| Патерн | Що може означати |
|---|---|
| Лінія повільно зростає | Нормальне зростання через трафік, logs або накопичені дані |
| Різкий стрибок | Великий import, сплеск logs, невдалий cleanup або неочікуване зростання файлів |
| Лінія близько до верхньої межі графіка | Серверу потрібен cleanup або більший диск |
Якщо використання диска зростає щодня, не чекайте критичного сповіщення. Заплануйте cleanup або розширення storage до того, як сервер стане нестабільним.
Nginx Validation
Панель Nginx Validation показує, чи остання перевірка конфігурації Nginx завершилася успішно.
Nginx відповідає за домени трекера та routing HTTP/HTTPS traffic. Якщо validation failed, нову або змінену конфігурацію домену може бути небезпечно публікувати.
| Status | Значення | Що робити |
|---|---|---|
success |
Остання Nginx validation пройшла успішно | Дія не потрібна |
failed |
Остання validation завершилася помилкою | Прочитайте validation error і перевірте відповідний domain або configuration |
| No Validation Snapshot | Ще немає опублікованого validation result | Це може бути нормально для свіжого setup |
Відкрийте Nginx files, коли потрібно порівняти available site files з enabled references. Якщо показано error, використовуйте його точний текст як початкову точку для troubleshooting.
Certificate Diagnostics
Таблиця Certificate Diagnostics допомагає перевірити HTTPS readiness для enabled domains.
| Колонка | Значення |
|---|---|
Domain |
Hostname, який перевіряється |
Certificate status |
Поточний стан сертифіката, наприклад pending, active, failed або expired |
A record |
Чи вказує DNS A record домену на сервер трекера |
Expires |
Час завершення дії сертифіката |
Last attempt |
Остання спроба issue або renewal сертифіката |
Failures |
Кількість невдалих спроб |
Failure |
Остання причина помилки, якщо вона є |
Типові ситуації з сертифікатами:
| Ситуація | Ймовірна причина | Рішення |
|---|---|---|
DNS not ready |
A record домену ще не вказує на сервер трекера | Виправте DNS і дочекайтеся propagation |
No certificate |
Домен enabled, але сертифіката ще немає | Спочатку перевірте DNS, потім дочекайтеся issue сертифіката |
Failed |
Issue або renewal сертифіката завершився помилкою | Прочитайте failure reason і перевірте DNS, public IP та доступність Let's Encrypt |
Expired |
Сертифікат більше не валідний | Обробіть терміново, бо браузери можуть блокувати домен |
Сповіщення про сертифікати стають важливішими, коли наявний сертифікат скоро закінчується або вже expired.
Перевірте discards кампанії
Перейдіть у Discards через sidebar панелі керування.
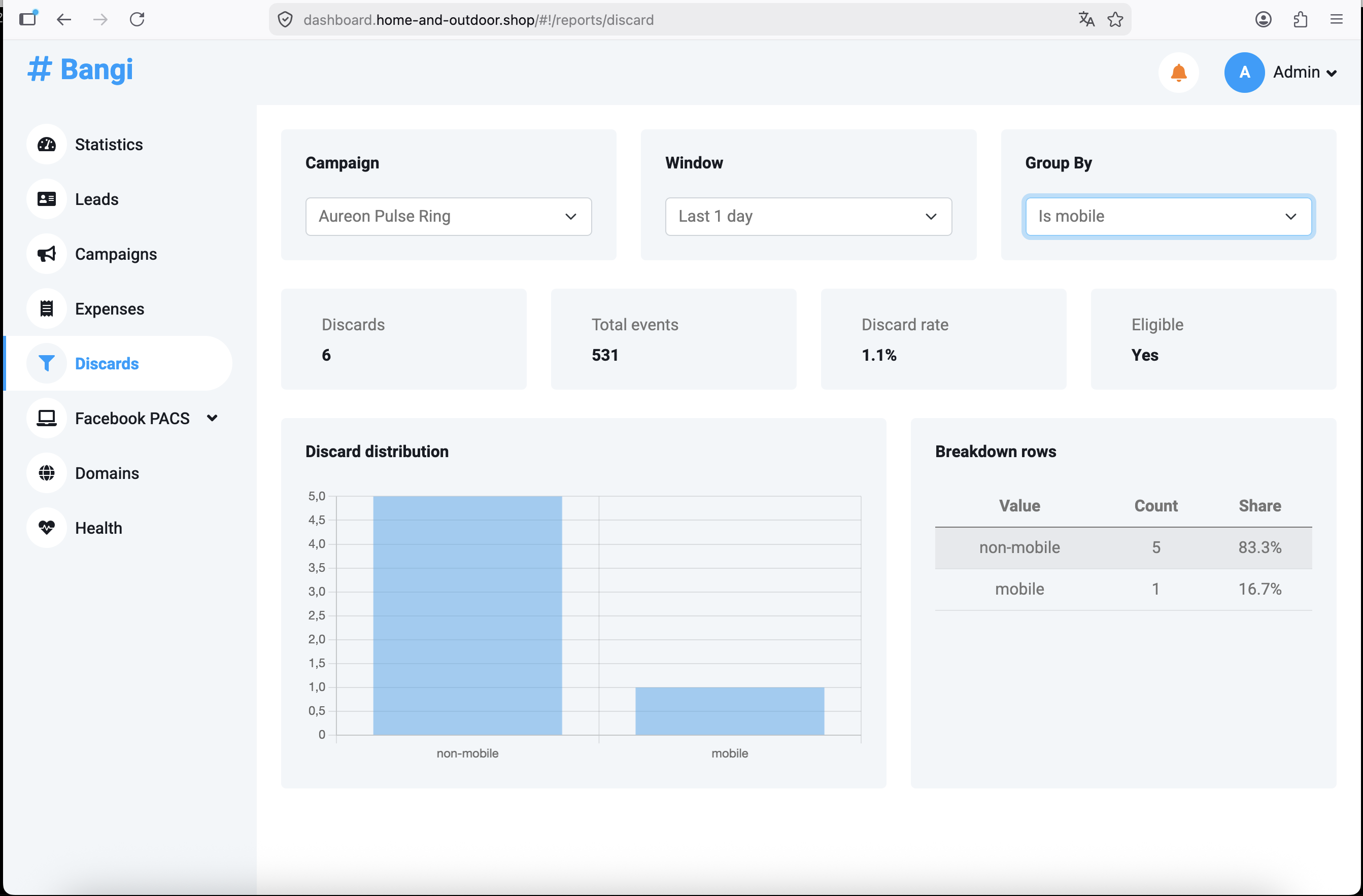
Discard означає, що відвідувач дійшов до кампанії, але трекер не зміг направити цей візит через жоден matching flow. Discards зазвичай з'являються через занадто строгі flow rules, відсутній fallback routing, disabled destinations або трафік, який не відповідає очікуваним умовам за країною, пристроєм, браузером чи bot status.
Сторінка Discards допомагає відповісти на запитання:
- Яка кампанія має unmatched traffic?
- Скільки events було discarded?
- Яка частка recent traffic була discarded?
- Які країни, browsers, operating systems, devices, mobile states або bot states є в discarded traffic?
Виберіть Campaign, Window і Grouping
Використовуйте фільтри вгорі сторінки Discards.
| Фільтр | Опис |
|---|---|
Campaign |
Кампанія для перевірки |
Window |
Період: last 5 minutes, last 1 hour або last 1 day |
Group By |
Вимір, за яким буде розбито discarded traffic |
Доступні dimensions для grouping:
| Group By | Що перевіряти |
|---|---|
Country |
Чи є трафік із країни, для якої немає matching flow |
Browser family |
Чи browser rules не виключають відвідувачів |
OS family |
Чи operating system rules не виключають відвідувачів |
Is mobile |
Чи mobile або desktop traffic не має route |
Device family |
Чи виключено конкретний device type |
Is bot |
Чи bot filtering пояснює discarded traffic |
Прочитайте Discard Summary
Summary cards показують:
| Метрика | Значення |
|---|---|
Discards |
Кількість discarded events у вибраному window |
Total events |
Загальна кількість tracked events, використана для розрахунку discard |
Discard rate |
Discards, поділені на total events |
Eligible |
Чи достатньо трафіку, щоб rate був змістовним |
Малі числа можуть створювати шум. Система вважає кампанію eligible для сповіщень про discards лише після того, як є достатньо recent events. Це не дає одному або двом раннім visits запускати сповіщення.
Прочитайте Distribution
Графік і таблиця показують, де discards сконцентровані найбільше.
Приклади:
| Що ви бачите | Що це може означати |
|---|---|
| Більшість discards з однієї країни | Немає flow для цієї країни або country rule занадто строгий |
| Більшість discards від mobile users | Flows можуть таргетувати лише desktop, або mobile routing відсутній |
| Більшість discards від bots | Bot rules можуть працювати очікувано |
| Discards розподілені між усіма значеннями | Можливо, відсутній default або fallback flow |
| Discards почалися нещодавно | Причиною може бути recent зміна flow, rule, domain або destination |
Використовуйте distribution, щоб вирішити, яке campaign flow rule перевіряти першим.
Виправте типові проблеми
| Проблема | Ймовірна причина | Рішення |
|---|---|---|
| Кампанія має багато discards | Частина трафіку не потрапляє в жоден flow | Додайте або скоригуйте matching flow |
| Discarded лише одна країна | Country rule не включає цю країну | Додайте країну до потрібного flow або створіть окремий flow |
| Mobile traffic discarded | Flow rules таргетують лише desktop | Додайте mobile routing або змініть device condition |
| Bot traffic discarded | Bot filtering може бути очікуваним | Підтвердьте, чи це нормально для кампанії |
| Discards з'явилися після редагування кампанії | Нове rule занадто строге або fallback було видалено | Перевірте останні зміни flows |
| Discards високі за всіма dimensions | У кампанії може не бути широкого fallback flow | Додайте default flow для traffic, який не підходить під specific rules |
| Certificate failed або expired | Є проблема з DNS або certificate issuance | Виправте certificate issue через Health перед повторним тестуванням traffic |
| Nginx validation failed | Опублікована web server configuration неконсистентна | Перевірте validation error у Health |
| Disk usage is critical | На сервері майже закінчилося місце | Звільніть disk space або збільшіть storage сервера |
Рекомендований порядок перевірки
Коли щось виглядає неправильно, дійте в такому порядку:
- Відкрийте сповіщення і знайдіть повідомлення з найвищою severity.
- Якщо сповіщення згадує disk, telemetry, certificate або Nginx, відкрийте
Health. - Якщо сповіщення згадує campaign discards, відкрийте
Discards. - Спочатку виправте найконкретнішу проблему: expired certificate, failed Nginx validation, critical disk usage або missing campaign route.
- Згенеруйте невелику кількість test traffic.
- Повторно перевірте сповіщення,
HealthіDiscards. Якщо сповіщення все ще видно після виправлення, дочекайтеся наступного автоматичного refresh або оновіть dashboard вручну.
Практичні приклади
Приклад: сповіщення про сертифікат
Сповіщення показує:
Certificate renewal failed for example.com and expires within 7 days.
Відкрийте Health, знайдіть example.com у Certificate Diagnostics і перевірте A record, Last attempt, Failures та Failure.
Якщо A record не налаштований, спочатку виправте DNS. Якщо DNS правильний, використовуйте failure reason для подальшого troubleshooting.
Приклад: сповіщення про campaign discard
Сповіщення показує:
Campaign "Aureon Pulse Ring" has discards. 5m: 1/25 (4.0%), 1h: 3/45 (6.7%), 1d: 12/55 (21.8%). Review flow routing.
Відкрийте Discards, виберіть Aureon Pulse Ring, оберіть Last 1 hour і згрупуйте за Country, Is mobile або Is bot.
Якщо одне значення домінує в таблиці, перевірте flow rules, які мали б обробляти такий traffic. Якщо зачеплені всі значення, перевірте, чи є в кампанії fallback flow.
Приклад: сповіщення про stale telemetry
Сповіщення повідомляє, що host disk telemetry stale.
Відкрийте Health і перевірте Last received. Якщо timestamp старий, dashboard може вже не знати поточний стан диска. Перевірте telemetry job на сервері перед тим, як покладатися на значення disk usage.
Чекліст
Використовуйте цей чекліст, коли причина системної проблеми не очевидна:
- Спочатку перевірте сповіщення з найвищою severity.
- Визначте, проблема інфраструктурна чи пов'язана з campaign routing.
- Для infrastructure issues відкрийте
Health. - Для campaign routing issues відкрийте
Discards. - Перевіряйте DNS перед troubleshooting сертифікатів.
- Перевіряйте Nginx validation після змін domain або certificate.
- Перевіряйте disk usage перед аналізом дивних write, logging або background job failures.
- Перевіряйте discard distribution перед зміною кількох flow rules.
- Після кожного fix протестуйте невеликою кількістю traffic і повторно перевірте дзвіночок сповіщень.
- Пам'ятайте, що сповіщення автоматично оновлюються приблизно раз на 10 хвилин, тому resolved сповіщення може не зникнути миттєво.
Потрібна допомога?
Якщо не вдається знайти або виправити проблему, напишіть у підтримку Bangi на support@bangi.tech. Додайте текст сповіщення, назву кампанії або домену, скріншоти з Health або Discards і коротко опишіть, що вже перевірили.